DEEP LEARNING — CONVOLUTIONAL NEURAL NETWORKS (CNN)
What is Translation Invariance? What is the Main Difference Between Invariance and Equivariance in CNN? Why do Convolutional Neural Networks have Translation Invariance?
The term translation invariance is often seen when reading papers related to COMPUTER VISION. Translational Equivariance and Translational Invariance are frequently confused but both of them different properties of CNN.
1- What is translation invariance?
Invariability means that you can recognize the target specialities even if its appearance changes slightly. So we want objects in the image to be successfully identified. Objects in an image can take different forms, such as can be scaled, translated, rotated or even viewing angles and different lighting conditions.
Various Invariances:
- Size Invariance
- Translation Invariance
- Perspective (Rotation/Viewpoint) Invarience
- Lighting Invarience

2- What is the Main Difference Between Invariance and Equivariance in CNN?
Translation invariance: means that the system produces exactly the same response (output), regardless of how its input is translated.
- In Euclidean geometry, translation is a geometric transformation that means moving an image or every point in space the same distance in the same direction.
Translation equivariance: means that the system works the same in different locations, but its response changes as the target location changes. For example, the instance splitting task needs to be translated and varied, and if the target is translated, the output instance mask should also change accordingly.

The recent FCIS article mentioned that a pixel may be the foreground in a certain instance, but it may be the background in an adjacent instance, that is, the same pixel has different semantics in different relative positions, corresponding to different responses, which is also translation homogeneity.
Math Perspective Group Homomorphism and Group Isomorphism

Equivariance can be formalized using the concept of a G-set for a group G. This is a mathematical object consisting of a mathematical set S and a group action (on the left) of G on S. If X and Y are both G-sets for the same group G, then a function
- f : X → Y is said to be equivariant if f(g·x) = g·f(x) for all g ∈ G and all x in X.
Equivariant maps are homomorphisms in the category of G-sets (for a fixed G). Hence they are also known as G-morphisms, G-maps, or G-homomorphisms. Isomorphisms of G-sets are simply bijective equivariant maps.
What’s Convolution? What’s intuition behind Convolution?
Convolution represents a mathematical operation on two functions. As there can be applied different mathematical operations such as addition or multiplication on two different functions, in the similar manner, convolution operation can be applied on two different functions. Mathematically, the convolution of two different functions f and g can be represented as the following:
- (f ∗ g)(x) = f(x) ∗ g(x) = ∫f(α)g(x–α)dα

The intuition behind convolution of f and g is the degree to which f and g overlaps when f sweeps over the function g. Here is animation representing convolution of two box functions. Note how the convolution results in a triangle when box functions overlaps with each other.
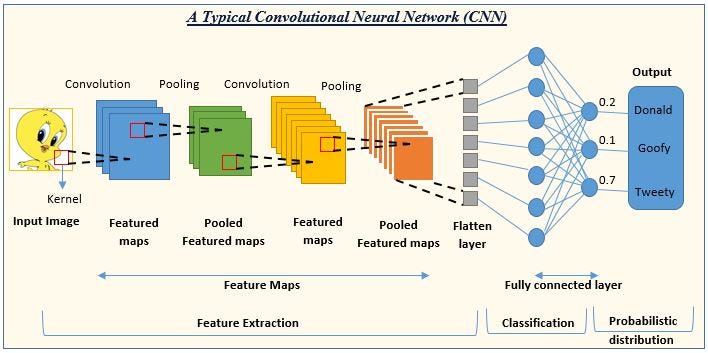
3- Why do Convolutional Neural Networks have Translation Invariance?
The figure below is just an example to illustrate this problem. There is a face in the lower left corner of the input image, and after convolution, the features of the face (eyes, nose) are also located in the lower left corner of the feature map.

If the face feature is in the upper left corner of the image, then the corresponding feature after convolution is also in the upper left corner of the feature map.

In neural networks, convolution is defined as a feature detector at different locations, which means that no matter where the target appears in the image, it will detect the same features and output the same response. For example, if a face is moved to the lower left corner of the image, the convolution kernel will not detect its features until it is moved to the lower left corner.
Convolution: Simply put, the image is translated, and the representation on the corresponding feature map is also translated.
Pooling: For example, maximum pooling, it returns the maximum value in the receptive field, if the maximum value is moved, but still in the receptive field, then the pooling layer will still output the same maximum value. This is a bit of a translation that doesn’t change.So these two operations together provide some translation invariance, even if the image is translated, convolution guarantees that its features can still be detected, and pooling is as consistent as possible.
Sources:
- Convolutional Neural Network: An Overview (analyticsvidhya.com)
- machine learning — What is translation invariance in computer vision and convolutional neural network? — Cross Validated (stackexchange.com)
- Fully Convolutional Instance-Aware Semantic Segmentation (thecvf.com)
- msracver/FCIS: Fully Convolutional Instance-aware Semantic Segmentation (github.com)
- Elementary group — Wikipedia
- Group homomorphism — Wikipedia
- G-set in nLab (ncatlab.org)
- Why do convolutional neural networks have translation invariance? _AI future blog — CSDN blog
